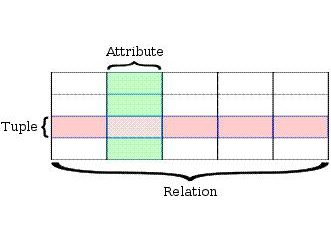
verteilte Datenbanken
Verstreute, oder, wenn es richtig ist zu nennen, verteilte Datenbank – es ist eine solche Datenbank, die eine Anzahl von Computern durch ein Netzwerk, von denen jeder eine lokale Datenbank verbunden ist. Die Gesamtheit aller dieser Software und Hardware schafft eine gemeinsame Datenbank. Verteilte Datenbank außerhalb aussehen wie gewöhnliche lokale Datenbank, ihre Hardware – Anordnung sind die Benutzer nicht sichtbar. Verteiltes Steuersystem steuert alle Speicherknoten und liefert Daten-Konnektivität.
Kristofer Deyt, bekannte Datenbank-Experten von Weltruf, hat zwölf wichtigsten Merkmale identifiziert, die alle verteilten Datenbanken haben sollte: 1) die lokale Autonomie, 2) Dauerbetrieb, 3) unabhängigen Knoten, 4) transparent Fragmentierung, 5) die Transparenz der Lage, 6) Verarbeiten spezifische Abfragen, 7) transparent Replikation, 8) unabhängig von der Ausrüstung, 9) verteilen Transaktionsverarbeitung, 10) Netzwerktransparenz, 11) unabhängig von dem Betriebssystem 12) unabhängig von den ausgewählten Datenbanken.
Betrachten Sie die wichtigsten Qualitäten, die gemäß der Daten, werden alle verteilten Datenbanken haben, im Detail.
Lokale Autonomie bedeutet, dass jede Einheit unabhängig voneinander die Daten seiner Basis verwaltet.
Dauerbetrieb. An diesem Punkt K. Date wird gesagt, dass Zugriff auf die Daten sollte kontinuierlich und unabhängig davon vorgesehen sein, ob sie an einem beliebigen Knoten befinden. Auch sollte es keine Rolle, dass jede Operation wird die lokale Datenbank zur Zeit durchgeführt.
Unabhängige Knoten. In einem idealen System alle Knoten gleich sind und unabhängig voneinander. Jede Datenbank wird auf dem Knoten befindet liefert Daten in einem gemeinsamen Raum mit den gleichen Rechten. Alle Datenbanken, die eine verteilte Datenbank, in sich geschlossene und geschützt vor unbefugtem Zugriff machen.
Transparente Fragmentierung. Diese Funktion erfordert die interne Datenbank – Unterstützung verteilte Platzierung von Daten , die man in der Tat sind.
Standorttransparenz. Benutzer, die in verteilten Datenbanken zugreifen will, sollen nicht wissen, etwas über den Knoten physikalisch zur Verfügung steht, die erforderlichen Informationen.
Abfrageverarbeitung verteilt. Die Datenbank muss Abfragen in SQL Probe perform verteilt.
Transparent-Replikation. Im Allgemeinen ist die Zirkulation – ist die Übertragung der geänderten Objekte von einer Datenbank zur anderen. Im Rahmen dieses Materials ist die Übertragung von Daten zwischen den Knoten in einer Weise zu verstehen, die die Unsichtbarkeit dieser Aktionen für den Benutzer zu gewährleisten.
Hardwareunabhängigkeit bedeutet, dass die Gateways Netzwerk mit verteilten Datenbanken alle Computermodelle wirken kann.
Die Verarbeitung von verteilten Transaktionen als ein Verfahren behandelt, um eine verteilte Datenbank unter Verwendung von Befehlen UPDATE zum Aktualisieren, DELETE, INSERT, während der Ausführung von denen nicht die Integrität und Konsistenz der Informationen in der Datenbank gespeichert ist verloren hat.
Unabhängigkeit von dem Betriebssystem nimmt an, daß Systemkomponenten können eine beliebiges Betriebssystem ausgeführt werden.
Netzwerk-Transparenz bedeutet, dass Zugriff auf alle Elemente einer verteilten Datenbank benötigt nur eine Netzwerkverbindung.
Unabhängigkeit von der Datenbank. Dies ist ein wichtiges Merkmal des Systems erfordert die Fähigkeit, mit allen verteilten Datenbanken von verschiedenen Anbietern, einschließlich der Möglichkeiten zu arbeiten, sollte auf die Suche und Updates zur Verfügung stehen.
Wie wir es als eine Struktur mit schwachen Bindungen sehen können, beschreibt die Definition von K. Daten für verteilte Datenbank, bestehend aus unabhängigen Knoten, die lokalen Datenbanken sind. Diese autonomen LBD und bieten Zugriff auf verteilte Datenbanken von verschiedenen Herstellern. Die Knoten bilden eine Verbindung zwischen dieser replizierbaren Daten sind. Die Topologie der verteilten Datenbank bildet die geografische Informationssystem und Datenreplikation fließt.


Latest posts
Wie kündige ich ein Abonnement im App Store auf Ihrem Telefon und PC?





Prüfung vor der Schwangerschaft – ist der Schlüssel zu einem gesunden Baby







